
Terrian Reconstruction
使用地形重建的行走策略
概述
问题:穿越稀疏立足的危险地形任务中四足机器人面临重大挑战,四足机器人需要生成精确的立足点。
历史方法的局限性:运动捕获系统或映射技术来为运动策略生成高度图需要专门的管道,并且经常引入额外的噪音。自我为中心的视觉系统的深度图像具有成本效益,但它们有限的视野和稀疏信息阻碍了地形结构细节的整合到隐式特征中
本文贡献:证明仅依靠本体感受和深度图像的端到端强化学习能够以高稀疏性和随机性来遍历风险的地形。
本文方法:使用地形重建作为视觉特征提取和运动生成的中间层,利用了高度图的信息,有效地表示并记住关键的地形信息。
方法理论
框架结构:基于端到端的RL,采用一组神经网络从原始深度图像输入与本体感受中生成目标关节角度,即运动策略,使用局部高度图作为中间表示。所有模型组件通过单阶段训练流水线训练,不需要为地形重建组件提供额外的训练阶段,并可以零样本迁移到真实机器人
整体框架可以分为两部分:Terrain-Aware Locomotion Policy, Terrain Reconstructor
Terrain-Aware Locomotion Policy
运动策略由 I-E estimator 和 actor 策略组成
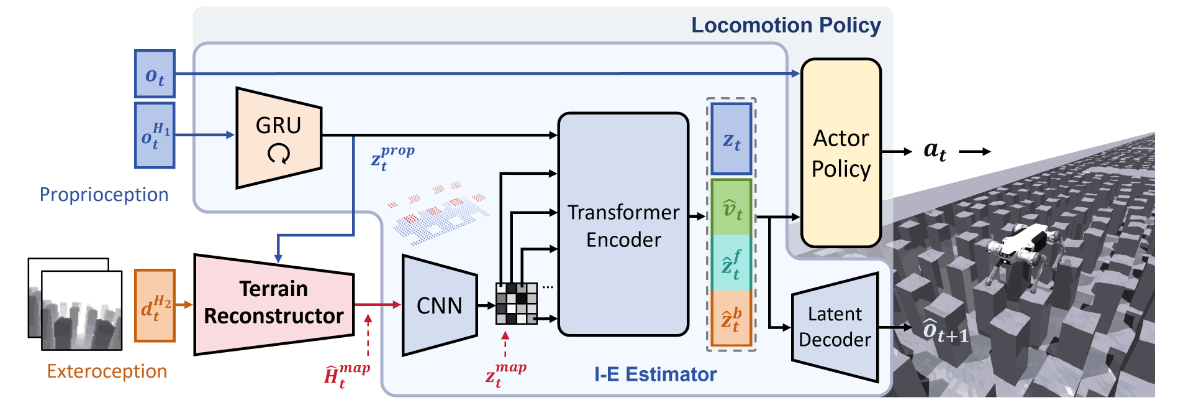
actor policy
输入:
- 最新的本体感觉输入 $ o_t \in \mathbb{R^{45}} $,其中 \(o_t = [ \mathbf{\omega}_t \quad \mathbb{g}_t \quad cmd_t \quad \theta_t \quad \dot{\theta_t} \quad a_{t-1} ]^T\) 分别为 身体角速度,重力矢量,速度命令,关节位置,关节角速度,历史动作。
- 估计速度 $ \hat{v_t} \in \mathbb{R^3} $,
- 四足周围的高度图编码 $ \hat{z}^f_t \in \mathbb{R^{16}} $,
- 身体周围的高度图编码 $ \hat{z}^b_t \in \mathbb{R^{16}} $,
- 潜变量 $ z_t \in \mathbb{R^{16}} $。
输出:关节动作 $ a_t \in \mathbb{R}^{16} $ ,由 PD 控制器完成动作
critic policy
输入:
- 本体感受 $ o_t $
- 特权观察:\(s_t = [v_t \quad c_t \quad H_t^f \quad H_t^b]^T\) 分别为 速度,脚步接触状态,足部高度图,身体高度图
I-E Estimator
采用基于多头自动编码器的I-E估计器来估算机器人的状态和特权环境信息。
输入:
- 时间序列的本体感知数据 $ o_t^{H_1}, H_1=10 $
- 局部地形重建图 $ \hat{H}_{map}^t $
输出:两层输出
- 自身感知特征:通过 GRU 获取 $ z_t^{prop} $
- 地形图特征:通过 CNN 获取 $ z_t^{map} $
- 估计向量:经过 transformer 将自身感知和地形图特征融合估计的特征
- 显示估计的速度 $ \hat{v}_t $
- 机器人身体周围的估计高度图 $ \hat{z}^b_t $
- 机器人四足周围的估计高度图 $ \hat{z}^f_t $
- 隐式编码特征 $ z_t $
- 预测的本体感知:使用 VAE 预测本体感受 $ o_{t+1} $,增强隐式估计的表征能力和捕捉时序中的动态规律
Terrain Reconstructor
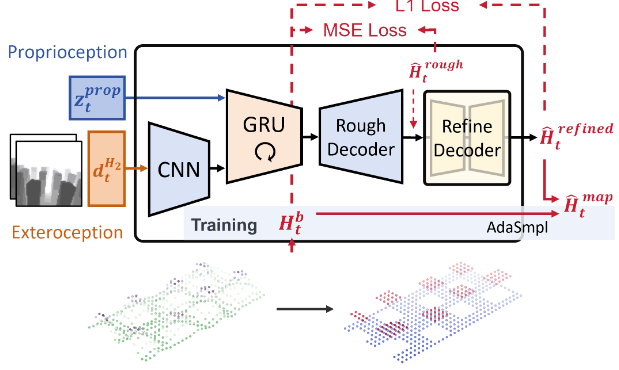
输入:
- 时间序列深度图:$ d_t^{H_2} $
- 本体感觉特征:$ z_t^{prop} $
输出:
- 中间输出:粗略高度图 $ \hat{H}_t^{rough} $
- 最终输出:精细高度图,进一步去除噪声、平滑边缘 $ \hat{H}_t^{refined} $
网络流程:
- CNN:对连续两帧深度图 $ d_t^{H_2} $ 进行视觉特征提取,提取局部地形提取、边缘、凹凸等低层次图像特征提取
- GRU:输入
CNN处理得到的视觉特征于本体感觉特征拼接向量的时序特征序列,引入记忆能力,如当前看不到但可能包含于上一帧中的区域 - MLP Decoder:即
Rough Decoder部分,将GRU输出解码为粗略高度图,与真实高度图使用MSE计算损失 - U-Net Decoder:即
Refine Decoder部分,将粗略高度图作为输入,进一步去除噪声,平滑边缘,得到精细高度图 $ \hat{H}_t^{refined} $,与真实高度图使用L1计算损失
损失函数:
- MSE:粗重建阶段使用
MSE可以获得平滑、整体合理、连续且近似正确的地形轮廓,因为MSE损失平滑且对异常值敏感,倾向于拉平错误大的区域 - L1:精细重建阶段使用
L1曼哈顿距离作为损失函数,可以减少过度平滑,保留更多真实地形中的非平滑特征,恢复真实地形中的高度差异,因为L1损失函数对细节变化更敏感,会保留尖锐边缘并且有助于恢复稀疏地形的特征
训练技巧:
- 两阶段重建,可以显著改善边缘模糊,地形起伏不自然的问题,尤其是边缘地形的准确性
- Adaptive Sampling:在训练初期不要盲目地使用噪声大的重建地形数据,而是根据训练效果决定是否使用更准确的地形真值(ground truth)来帮助策略更好地学习;使用真实地形的概率符合:$ p_{smpl} = tanh(CV(R)), CV(R) = \frac{标准差(reward)}{平均值(reward)} $,其中
CV(R)是每个episode的奖励的变异系数
优势:相比于原始深度图,重建的高度图结构更清晰、无噪声;弥补板上相机存在的视角小,易遮挡问题
模型训练
为了减轻两阶段训练引入的数据效率低下和信息损失,采用不对称的 actor-critic 结构和 PPO,使用单阶段的训练。
- 奖励:命令追踪、能耗、碰撞等,边缘惩罚等
- 地形课程设计:随着训练步数增加,逐渐以更高的概率使用更困难的地形
- 动作指令采样:前向速度随机采样,转弯命令
实验
实验平台
12 关节机器人 Lite3,使用 Intel Realsense D435i 使用 10Hz 频率采样深度图像,使用 TensorRT 在 Jetson Orin NX 上部署推理,使用 isaacgym 仿真环境
消融实验
两组消融实验,分别验证本文中提出的训练流程和模型结构是否有效
| 分类 | 实验名 | 测试内容 | 用途 |
|---|---|---|---|
| 训练流程 | HMap GT | 真实高度图 vs 重建高度图 | 上限性能对比 |
| w/o AdaSmpl | 有无自适应采样 | 看是否加速训练,稳定学习 | |
| w/o FtEdge | 有无脚边缘估计 | 是否对策略决策有关键影响 | |
| w/o TerProg | 有无课程式地形渐进 | 检查 curriculum 对探索效果 | |
| 模型结构 | w/o T-RCr | 用旧方法 (2D-GRU) 替代重建器 | 与之前PIE论文中方法比较 |
| w/o Prop | 去掉 proprioception | 检查多模态输入必要性 | |
| w/o GRU | 用 MLP 替 GRU 去掉时序记忆 | 评估记忆对重建稳定性作用 | |
| w/o Refine | 不精细化高度图 | 检查精度对策略的影响 |
仿真实验
每个实验都在 10 个随机生成的地形 上进行,使用 500 个机器人并行评估
评价指标:
- 成功率:成功前进
6米的机器人比例 - 穿越率:实际走过距离/总路程
- 平均边缘违规率(MEV):踩在边缘的次数
- 地形重建误差:最难地形等级上,机器人穿越 6 米过程中
terrain reconstructor的重建误差
真实世界实验
各个消融实验中的框架在真实世界中的实验表现
| 模块 / 策略 | 问题 / 失败原因 | 说明 |
|---|---|---|
| 原始完整框架 | 表现最好,强 sim-to-real 能力 | 所有模块协同有效 |
| w/o FtEdge | 脚落在边缘,滑落、踩空 | 缺少对边缘的处理或识别 |
| w/o TerProg | 学不到灵活策略,动作不现实 | 地形训练策略对泛化很关键 |
| w/o T-RCr | 真实中表现急剧下降,摔倒多 | 地形重建对安全落脚非常关键 |