
Wmp
基于世界模型的视觉腿部运动感知
概述
问题:如何在单阶段内同时训练感知与运动策略模块,使机器人能够直接从高维视觉输入生成运动策略?
挑战:直接从高维视觉学习往往数据效率低且优化困难。
历史方法的局限性:
- 教师-学生蒸馏范式
- 使用特权信息训练教师模型,再蒸馏到学生模型,并同时训练感知模块。
- 问题:
- 学生模型因泛化不足难以达到教师性能;
- 当特权信息与视觉观测存在差距时,性能差距进一步放大;
- 特权信息需要专门设计,不具备普适性。例如 scandot 在 tilt、crawl 场景下表现不足。
- 基于模型的强化学习(MBRL)
- 通过预测未来观测学习动态模型,将高维感知压缩成低维有意义的表示。
- 但传统方法多依赖于简单的 CNN 嵌入或 GRU,对复杂视觉结构的建模仍有限。
本文贡献:提出一种基于世界模型(World Model)的方法,利用递归状态空间模型(RSSM)在单阶段同时学习感知与策略,从而:
- 有效利用深度图像信息;
- 避免教师-学生蒸馏带来的信息损失;
- 缓解特权信息与视觉输入之间的差异问题。
方法理论
整体框架分为两部分:World Model Learning (RSSM) 与 Policy Learning (Asymmetric Actor-Critic)。
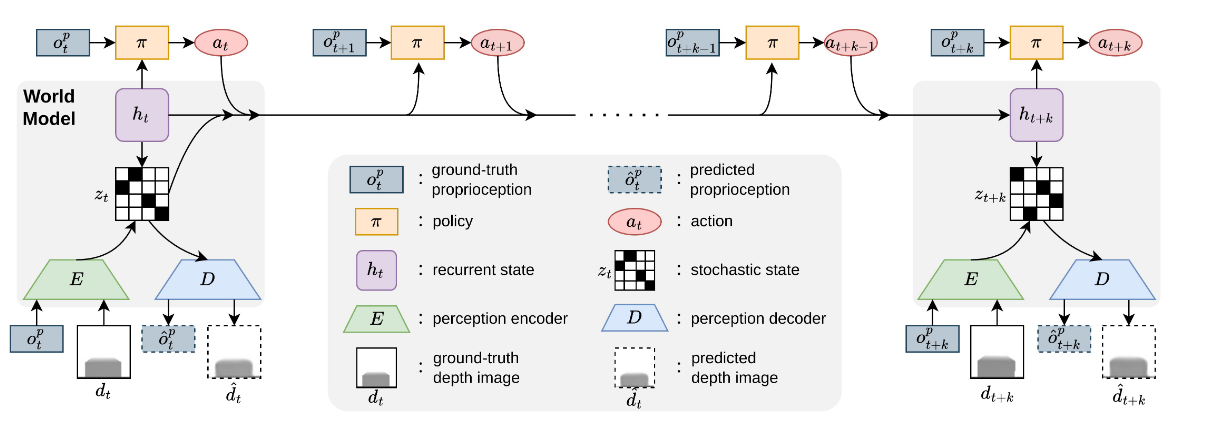
World Model Learning: RSSM
RSSM 的训练目标为:
\[L(\phi) = \mathbb{E}_{q_\phi}\Bigg[ \sum_{t=n\cdot k} -\ln p_\phi(o_t | z_t, h_t) + \beta \,\text{KL}\Big(q_\phi(\cdot | h_t,o_t)\,\|\,p_\phi(\cdot | h_t)\Big) \Bigg]\]其中:
- 递归隐状态更新:
\(h_t = f_\phi(h_{t-k}, z_{t-k}, a_{t-k:t-1})\) - 后验分布(感知约束):
\(z_t \sim q_\phi(z_t | h_t, o_t)\) - 先验分布(预测约束):
\(\hat{z}_t \sim p_\phi(z_t | h_t)\) - 观测重建:
\(\hat{o}_t \sim p_\phi(o_t | h_t, z_t)\)
损失解释:
- 第一项为 重建误差,保证模型能解释当前观测;
- 第二项为 KL 散度,保证预测潜变量与基于真实观测的潜变量一致。
Policy Learning: Asymmetric Actor-Critic
-
Actor:
\(a_{t+i} \sim \pi_\theta(a|o_{t+i}, \text{sg}(h_t))\)
仅依赖视觉观测与潜变量。 -
Critic:
\(a_{t+i} \sim \pi_\theta(a|o_{t+i}, \text{sg}(h_t), s^{pri}_{t+i})\)
输入包含特权信息(如速度、接触状态),训练更稳定。
其中 sg() 表示 停止梯度,避免对潜变量产生干扰。
关键点:RSSM 提供的隐状态 $h_t$ 成为策略学习的核心表征,使得策略能够高效利用视觉输入,并保持与特权信息训练一致的性能。
实验
从三个角度验证方法的有效性:
- 与现有视觉运动方法的比较
- 在仿真环境中,WMP 显著优于 Extreme Parkour 及其他基线策略。
- 世界模型的预测能力
- 通过 t-SNE 可视化,潜变量 $h_t$ 在不同地形上具有良好的区分度;
- 仿真中训练的 RSSM 能准确预测真实轨迹,表现出强泛化能力。
- 真实机器人评估
- 将策略部署在 Unitree A1 上,验证了从仿真到现实的可迁移性。
结论
本文提出的 基于世界模型的视觉腿部运动感知方法(WMP),通过 RSSM 学习到更具表达力的潜变量 $h_t$,在单阶段框架中实现了感知与运动策略的联合优化。相比于传统教师-学生方法和基于模型的 RL,WMP 在数据效率、策略性能和 sim-to-real 迁移性上均表现更佳。
未来工作中,可以尝试结合仿真数据与真实世界数据共同训练世界模型,这有望构建出更贴近现实的表征,从而进一步提升模型的泛化能力和真实环境中的表现。